Piece values
Note: all descriptions will be made for white pieces, but remember that chesSkelet plays with black pieces. So after running its small brain, the board will be reversed and the computer will be the black side.
Let me start by saying that my implementation will not do everything I’m explaining here. In order to keep things small I’ll be cutting some corners. Initially I thought that any scheme where K > Q > R > B > N > P would work, but it turns out it’s not that simple. Choosing the right piece values will simplify coding and the computer will make better decisions.
I’m using one byte to store the piece information. One bit will be used to store the piece color. In my mind, the highest bit (bit 7) makes more sense. If we need the “uncolored” piece value, we can clear bit 7 and no additional manipulation is needed.
So, let’s say that we use bit 7 of the square byte to store the color and the rest for the piece value:
b7 b6 b5 b4 b3 b2 b1 b0
C P P P P P P P (C= color bit, P= piece value bits)
This would leave enough room for a classical K=127 (infinite), Q=9, R=5, B=3, N=3, P=1.
However, we do not need to follow these values strictly. The only good thing about the AI looking only one move ahead (chesSkelet case) is that calculations where sacrificing a Queen for two Rooks do not make sense. Any K > Q > R > B > N > P scheme would work.
This said, we can try something a little more precise:
• It’s convenient to have all pieces with different values. This way, we can differentiate them directly by its values. Therefore, B and N shall both not be 3. (chesSkelet uses N=2, B=3).
• The King needs to be easily spotted from the rest of the pieces (i.e. checkmate detection). This is easy, since its value is much bigger, so, for instance b6 or b5 are only used by the king (programming note: a BIT 6, X instruction would identify the king for us).
• Optionally, it may be good to be able to uniquely identify pawns by leaving bit 0 only for them (chesSkelet is not doing it, but I’m considering it).
• Finally, we’ll see that the move valuation system introduces more constraints than the plain piece values.
With ChesSkelet, I’ve chosen to use bit 5 for color (1=white, 0=black). This is not a random choice. I use capital and small letters to represent pieces, and the “ASCII distance” between capital and small letters is 32, so I can use bit 5 of the piece value (b5=1 is 32 in decimal) to decide capital/small letter depending on the piece color.
This leaves my square scheme as follows (not exactly, but we´ll get there):
b7 b6 b5 b4 b3 b2 b1 b0
0 0 C P P P P P (C= color bit, P= piece value bits)
0 0 1 1 1 1 1 1 Example: C=white, P=31= King
0 0 1 0 1 0 0 1 Example: C=white, P=9= Queen
Move valuation
My piece value system is built around that fact that the computer is looking just 1 move ahead. For every board position, the computer builds a table with all the potential moves for its pieces. With that list, every move is evaluated.
The most basic approach to move valuation would be to capture any piece which is equal or more valuable than ours, just in case it is recaptured. Obvious, isn’t it? This system is the best you can get if the only information you have is the value of the piece you are moving and the value of the opponent’s piece in the target square.
ChesSkelet does a little better than that. For every move, 4 pieces of information are available:
• Origin square piece value (own piece)
• Target square piece value (opponent’s piece)
• Origin square attack status, telling if the computer piece is under threat.
• Target square attack status, telling us if the square where we are moving is under threat.
Things get a little more complex, but will also help the computer taking better decisions:

(Whites are capitals and Blacks are small letters)
In the two cases above, a decision taken with no information on the square attacked status would be wrong:
• In board 1, the Queen would capture the Rook, not knowing that the queen would be captured as well. The target square attacked status would help us preventing that.
• In board 2, the Rook would capture the Knight, which is wrong, since we´ll be losing the other Rook. Knowing the origin square attacked status would prevent that problem too.
So, in a simple manner, my move decision algorithm evaluates the move as follows (take into account that only legal moves are evaluated, so a piece cannot capture another piece with the same color):
1) Target piece: Whatever piece value is found in the target square is counted (+)
2) Origin piece:
a) If the origin square is attacked, the origin piece is counted too (+), since we save it by moving it.
b) If the target square is attacked, the origin piece is discounted (-), since moving it to the target square makes it a potential capture for the opponent.
Interestingly, this approach covers both origin and target squares being attacked, as the origin piece is being counted and discounted, making this move neutral, as the piece can be captured by the opponent in both squares.
Also, let me anticipate that most micro chess games will not announce checkmate, they need to actually capture the opponent’s king to finish the game.
As we will see later it is important to understand how many bits we need to store the pieces value. Let’s calculate the minimum king value (K=31 above is not optimal), the piece maximizing the number of bits needed:
• In order to avoid specific coding for capturing the king, the best possible move is capturing the opponent’s king, even in the least favorable conditions, a queen with the king’s square being defended:
+K (target square content= King) -9 (Queen falling in an attacked square) = +K-9
• The second best move would be an attacked Queen capturing the opponent’s Queen. With the current scheme that is:
+9 (target square content= Queen) +9 (Queen leaving his attacked square) = +18
• Therefore, in order for the first move to be preferred over the second:
K-9 > 18 --> K>27 --> K=28 would work.
• Another situation to consider, the worst possible valuation, which would be the King moving to an empty and attacked square: 0 - 28 = -28.
This is important, because we need to deal with negative values. To avoid negative values, I will add this (minimum+1)=29 to any piece valuation, so that all results are positive. The range for piece valuation would be:
• Maximum, attacked queen capturing king: (+28 + 9) + 29 = 66
• Minimum, King to an empty attacked square: (0 - 29) + 29 = 1
With K= 28 (00011100), bit 4 would still identify the king uniquely.
In general, this approach could be good, but in my case, as we´ll see later I don’t want to have such big compensated valuation of 66. Ideally, I’d like to use 5 bits or 6 bits maximum.
After several iterations, I’ve come to a slightly different valuation that would help the compensated valuation in 6 bits with Q=8 and K= 25. All the requirements above would be fulfilled and the compensated valuation would range from 1to 60.
Square weight
In order to give the computer some direction in its moves, we are not only looking at the captures, but also at where pieces are moving towards. This is how I represent a square value (this representation is aligned to the 16x8 byte board introduced earlier).
b7 b6 b5 b4 b3 b2 b1 b0
0 R R R 0 C C C (R= rank bits, C= column bits)
In more advances chess programming there are very complex schemes, depending on the piece and also on the game stage, but I could not afford anything like that, so I figured out a very simple scheme:
• Pieces would naturally move forward, so the further the rank, the better. Ideally, this gives us a 0-7 weight (3 bits).
Coding: shift (losing bits on the right end, not rotating) the square value 4 times to the right, and there you have it. The only other thing to take into account is that ranks in memory decrease vs. ranks in board increase, so instead of adding the result we subtract it for calculation.
• Also, center pieces activity should be favored. Here I tried different schemes, like looking up an array that would give us a column weight. Finally, I found another method, not so precise, but much cheaper in size. If I take the square value and do this:
ADD A, 2; AND 4
It’s not perfect, but it clears the ranks and gives higher weight to the center columns (and only takes 4 bytes!). This is the column weight produced:
c0 c1c2 c3 c4 c5 c6 c7
2 3 4 5 6 7 0 1
Aggregating rank and column weight we obtain a board heat map which looks like this.
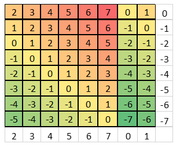
I could have done it differently with other value in ADD and AND operations, but this particular tuning also helps me preventing opening the C column (which becomes F for black. Remember that computer plays with black pieces) at least initially, and also gives the highest weight to the initial king square and F6, so a piece not finding obstacles will tend to go there.
Obviously, this approach is not dynamic. It won’t chase the King as it moves, but being as weak as ChessKelet is, it’s not likely that the human player is moving his King a lot.
Now we´ll see how to combine the piece valuation with the square weight.
Piece valuation + Square weight
In the next step, my intention is to combine both Piece Valuation (PV) and the target Square Weight (SW) in a single byte. That would give us the move value that we can compare with the rest of the candidate moves.
It seems obvious that with this scheme PV needs to have a higher value than the SW. Therefore, PV will occupy the higher bits of the final value byte.
Now we need to sort out an inconvenient: PV needs 6 bits and SW needs 3 bits, and all that info needs to fit in 8 bits. Both values combination with the appropriate PV prioritization would look like this:
b7 b6 b5 b4 b3 b2 b1 b0
PV PV PV PV PV PV/SW SW SW
We need to decide what to do with the overlapping bit 2. Three possible options:
1. Keep the overlapping: by leaving this bit open for both uses it may happen that a move with a good SW scores better than a pawn capture. Do we really want that? It would not be so bad, I guess.
2. Give it to the square weight: we would lose the less significant bit of the piece valuation. That may lead to wrong capture decisions.
3. Give it to the piece valuation: this would leave us with a very small granularity for the SW, but it would provide a reliable result.
I lean towards options 1 and 3. I’m still experimenting with both.
All of the above is implemented in ChesSkelet with around 70 bytes.