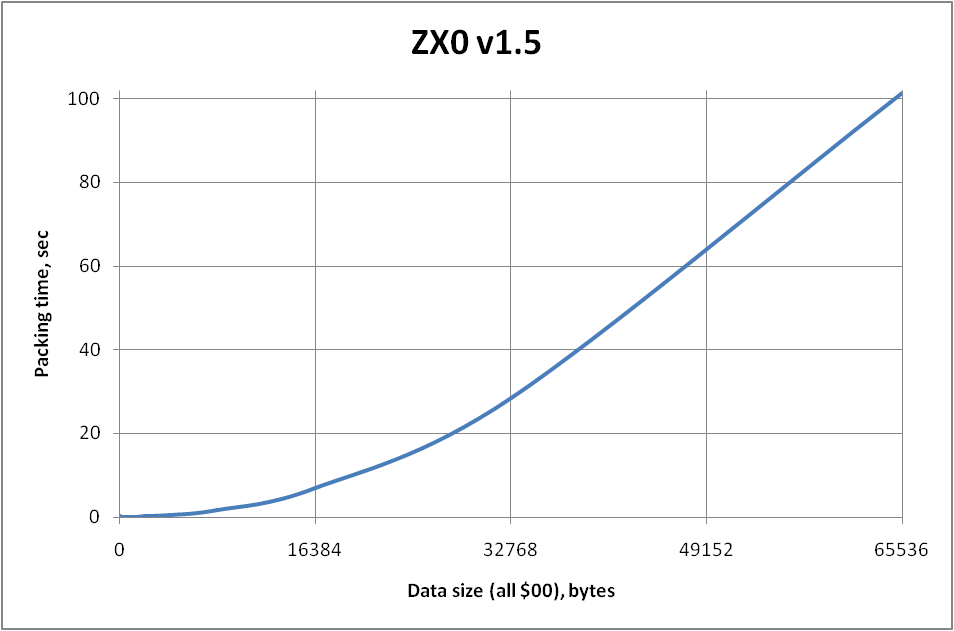
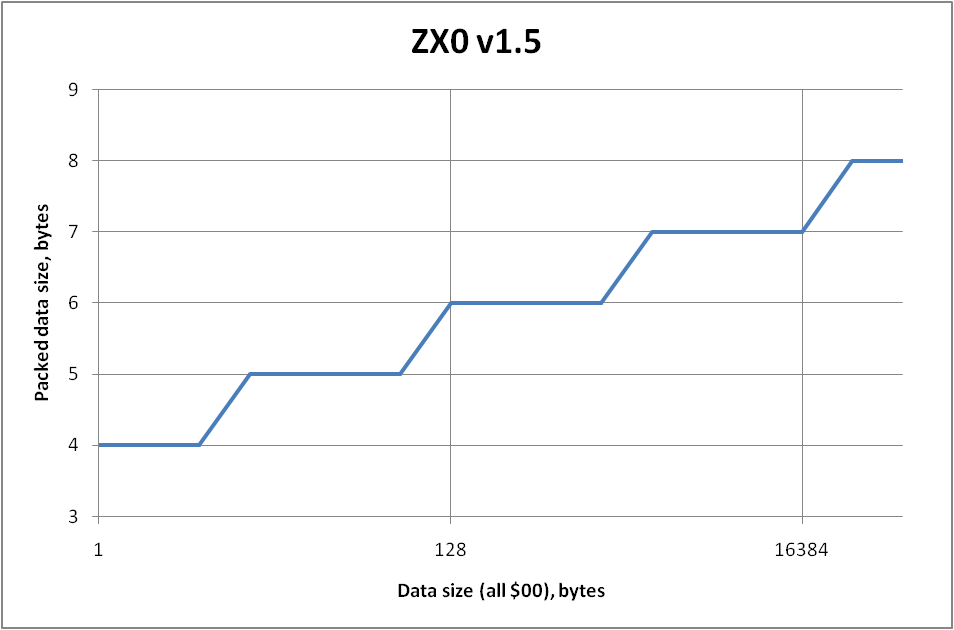


It's slower when there are lots of matches therefore more combinations to be analyzed. Fortunately it also means more opportunities for better compression. Don't you think that compressing from 65536 to 8 bytes was worth the wait?
nopeEinar Saukas wrote: ↑Thu Oct 14, 2021 3:35 pm Don't you think that compressing from 65536 to 8 bytes was worth the wait?
i will do it laterEinar Saukas wrote: ↑Thu Oct 14, 2021 3:35 pm If so, what's your platform, compiler and compile options? Also could you please try the most recent version?
OK, the multi-thread version of the ZX5 compressor is now available here:Einar Saukas wrote: ↑Tue Oct 12, 2021 10:25 pmSure. However memory management in current C implementation is based on reference counting, which would be inefficient across threads. This will require another language with GC and lightweight threads, preferably also resizeable hash tables. I will probably try Kotlin, unless anyone has a better idea?
Ouch!
AFAIK the memory limit for 32 bit applications is 2Gb only.jimmy wrote: ↑Wed Oct 20, 2021 1:47 pm Based on this I don't think my first test would ever have worked as the 32-bit zx5.exe would unlikely be able to address more than 4Gb. The zx5 quick mode took just over 150 minutes to complete! Even if zx5 was 64-bit, it seems to imply I'd need at least 16Gb of RAM to perform this task.
No, I don't think it's a reliable estimate.jimmy wrote: ↑Wed Oct 20, 2021 1:47 pm Is it true to say that if a quick zx5 result is larger/greater than a quick zx0 result, then the 'full compression' versions will also come out as zx5 is larger/greater than zx0 output? (ie: is this a quick test to save wasting hours compressing a file that zx0 would do better anyway?)
It should run much faster. Don't forget to specify memory size, as described in the project documentation!
You are welcome!andydansby wrote: ↑Sat Nov 06, 2021 1:35 pm I've started using ZX0 in my development scheme. Loving it.
An example project that I've started playing with is at https://github.com/andydansby/Vortex2_P ... 2_compress to compress Vortex tracker songs. Here I am creating a buffer and uncompressing the song to it to play. Next to add multiple songs.
Nice compression. Takes a 11302 byte song and compresses it to 4019 bytes.
Thanks Einar.

Code: Select all
device ZXSPECTRUM48
MEM_END EQU 65535
displace EQU MEM_END - file_end + 1
org 50000
display "start ", /A, $
start:
ld sp, 24999
; fill screen with pattern
ld hl, 16384
ld de, 16385
ld bc, 6911
ld (hl), e
ldir
; move packed data and unpacker to end of memory
ld hl, file_end-1
ld de, MEM_END
ld bc, file_end - file_start
lddr
jp unpacker + displace
; data and code from this point will be moved
file_start:
incbin "Andy Green - Flashback (2018).scr_norm.zx0"
include "dzx0_standard.asm"
unpacker:
ld hl, file_start + displace
ld de, 16384
;ld de, 49152 ; <=== crash
push de
call dzx0_standard + displace
pop hl
; copy unpacked picture to screen
ld de, 16384
ld bc, 6912
ldir
; dead end to indicate all went ok
xor a
loop:
xor %111
out(254),a
jr loop
file_end:
savesna "test.sna", start
Arrgh, silly meEinar Saukas wrote: ↑Tue Dec 21, 2021 6:56 pm It seems you are compiling the decompressor at one address but executing it at another.
When you moved the compiled code, the CALL instruction was still invoking a sub-routine at the original address. I'm guessing you did not override the old address when decompressing directly to screen, so it still worked (by accident).
Yes, you are right. Thank you again. I rewrote part of code with disp/ent, and it works now.Einar Saukas wrote: ↑Tue Dec 21, 2021 9:18 pm When you moved the compiled code, the CALL instruction was still invoking a sub-routine at the original address.
Code: Select all
device ZXSPECTRUM48
MEM_END EQU 65535
move_size EQU file_end - file_start
org 50000
start:
ld sp, 24999
; fill screen with pattern
ld hl, 16384
ld de, 16385
ld bc, 6911
ld (hl), e
ldir
; move packed data and unpacker to end of memory
ld hl, move_end-1
ld de, MEM_END
ld bc, move_size
lddr
jp unpacker
; ---------------------------
; data and code from this point will be moved on start
move_start:
; compile part of program to this ORG address
DISP 65535 - (move_size) +1
file_start:
incbin "Andy Green - Flashback (2018).scr_norm.zx0"
include "dzx0_standard.asm"
unpacker:
ld hl, file_start
;ld de, 16384
ld de, 49152 ; <=== crash
push de
call dzx0_standard
pop hl
; copy unpacked picture to screen
ld de, 16384
ld bc, 6912
ldir
; dead end to indicate all went ok
xor a
loop:
xor %111
out(254),a
ld b, a
pause:
djnz pause
jr loop
file_end:
ENT
move_end:
; ---------------------------
savesna "test.sna", start
ZXRar with 2-byte blocks TOTAL = 603460, including file headers (lost to exomizer and ZX0)Alone Coder wrote: ↑Wed Jan 20, 2021 5:31 pmTemporarily added 2-byte blocks in NedoOS version:Alone Coder wrote: ↑Wed Jan 20, 2021 4:02 pm calgary - 98571 (lost to Exomizer3)
canterbury - 27939
graphics - 163173 (better than others)
music - 63721
misc - 254202
RAR headers included.
Decompressor size is 342 bytes (uses 1566 bytes for temporary buffer).
TR-DOS version of ZXRar optionally supports compression with 2-byte blocks (helpful for code), with 386-byte decompressor. It has to be tested too.
calgary - 98525
canterbury - 27911
graphics - 163943
music - 62740
misc - 250341
Check if you downloaded it correctly. You are supposed to click on the "Download" button.
An easily understood (though not hugely efficient) way to compress a screen that's got lots of empty character cells is to start with the attributes, and exploit the fact that no-one in their right mind would ever use the FLASH bit. So you scan your screen for empty character cells, and if you find one, set the FLASH bit of that attribute. Then you store your data as one byte of attribute, followed by eight bytes of pixel data, but you only store the pixel data if the FLASH bit is not set. Otherwise, you move straight on to the attribute for the next character cell.TMD2003 wrote: ↑Wed Sep 21, 2022 11:49 pm I've also taken to analysing the 6912 bytes, piece by piece, writing a load of LD HL,***** then LD (HL),*** and the odd LDIR routine to draw it effectively byte by byte, leaving out all the huge chunks of zeroes. Effectively I'm compressing the screen by hand, which is lengthy and tedious.

...aaand again the example is that screen compressor of mine, LgK aka Lethargeek KompaktJoefish wrote: ↑Thu Sep 22, 2022 11:28 am An easily understood (though not hugely efficient) way to compress a screen that's got lots of empty character cells is to start with the attributes, and exploit the fact that no-one in their right mind would ever use the FLASH bit. So you scan your screen for empty character cells, and if you find one, set the FLASH bit of that attribute. Then you store your data as one byte of attribute, followed by eight bytes of pixel data, but you only store the pixel data if the FLASH bit is not set. Otherwise, you move straight on to the attribute for the next character cell.
When you come to unpack that stream of data, you first take a byte, check the top bit, and if it's set, you erase that bit, write the byte to the attribute, then write 0s into the pixel bytes for that character cell. If the top bit isn't set, then copy it up as an attribute, then copy the next eight bytes into the pixel bytes of that character cell.
Of course your screen data can't get any lower than 768 bytes (768 empty characters), but it's a start.
And then there are far more complex approaches you can take once you get the hang of it! But however elaborate the mechanism, decoding is the same. Read some signal bits or bytes from the compressed data, and depending on what you just read, either copy some more raw data from the stream or do something special like pad with blanks or copy something from earlier, or from a prepared 'dictionary' of common byte sequences.
In this page, clicking on a filename will take you to another page, not directly to the actual file. So if you right clicked and saved it, you actually saved a webpage, not an executable file.TMD2003 wrote: ↑Thu Sep 22, 2022 9:25 amI was using the version found here:
https://github.com/einar-saukas/ZX0/tree/main/win
"Updated executables" seemed like the right place to go...
I've always found it unnecessarily annoying, especially since a fair few projects of this type are hosted there. Sourceforge is a lot easier to navigate.Einar Saukas wrote: ↑Fri Sep 23, 2022 2:33 pm The Github interface can be quite confusing, that's not my fault!
The standard version of the decompressor uses 4 bytes of stack.
Each decompressed byte is directly written to the destination.


