That's only going to make a difference when there is a choice of ways to get to the goal though and they are forced to visit either the red or blue node and it picks the blue one incorrectly.
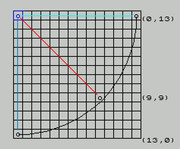
You could always use a lookup table for the distance if you are really worried about it but you'll need to use more than 8 bits for the cost then. You only need 1 quadrant so similar to the diagrams I drew earlier like this, probably best to flip it though like so, so the origin is in the top left corner at (0, 0)
You'll need a lookup table size of ((max map size/2)+1)^2 * precision bits for that (but probs want to align each row to a power of 2 to easier convert row, column to index in table?).
EDIT: Actually you only need a bit more than half of the table (one octant plus a bit more for one diagonal and one full horizontal row) since the table is symmetric i.e d(x,y) = d(y,x) so it is the same as it's transpose (flip along leading diagonal)... but that would make lookup more complicated.
i.e. you could store this
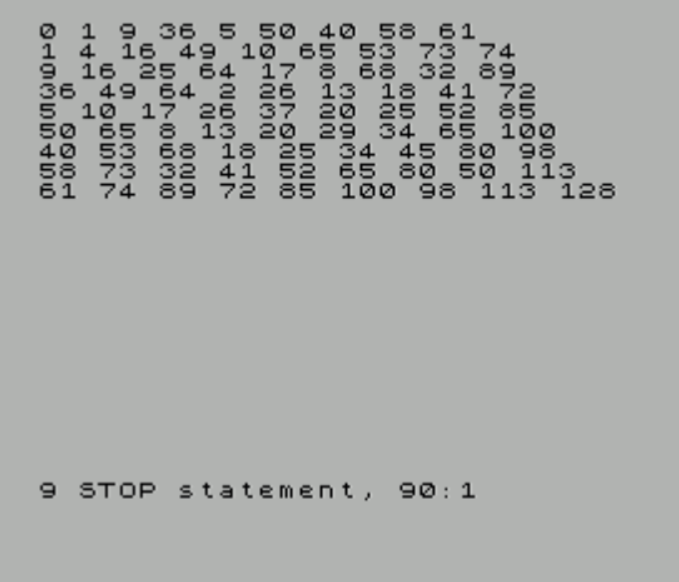
Code: Select all
0 2 4 6
3 5 7
6 8
9
which can pack as
0 2 4 6 3 5 7 6 8 9
I could probably work out what the accessor function for that is if I could be bothered

There's n(n+1)/2 entries anyway (and you won't need to store 0 either since d(x,x) = 0, so n(n+1)/2-1 entries to pack a lookup range of -n to n in both axes).
Alternatively (and you'll need a multiply for this of course) you could work out dx^2 + dy^2 (or you can use a table of squares for that too so you don't need a multiply) and then have a square root lookup table so
0 -> 0
1 -> 1
2 -> sqrt(2)
(you can't make 3 with a sum of 2 squares)
4 -> 2
5 -> sqrt(5)
etc.
You can either leave gaps in the table (will probably be quite large then) or else do a binary search looking for your value since the left hand side sequence is strictly increasing). EDIT: If you have gaps in the table you might save more space overall though since you don't have to store the key values then (sequence on the left above)
To find out what entries you would not need in the lookup table you can use this theorem to check you haven't made a mistake
https://en.wikipedia.org/wiki/Sum_of_tw ... es_theorem
I don't really like how they describe the result there though
To find out if an integer N can be expressed as a sum of 2 squares:
1) Factorise N. Get wolfram alpha to do that for you
2) If any of the odd prime factors (i.e. ignore factors of 2) have remainder 3 when divided by 4, they must occur to an even power
Example:
1234567890 factorises as
2 x 3 x 3 x 5 x 3607 x 3803 = 2 * 3^2 * 5 * 3607 * 3803
factor of 3 occurs to an even power, that's ok
3607 / 4 = 901 remainder 3. That's an odd power -> 1234567890 is NOT a sum of 2 squares
Less silly examples:
42 is not a sum of 2 squares, 42 = 2 * 3 * 7 and both 3 and 7 mod 4 = 3, so have odd powers in the prime factorisation
18 = 2 * 3^2 which although it has 3 as a factor and 3 mod 4 = 3, that occurs to an even power. So 18 is a sum of 2 squares (3^2 + 3^2).
I have a remarkable short proof of the result (well it's in a book I have), but this post is too small for me to fit it in
The case for whether a prime is a sum of 2 squares was proven by Fermat. A prime p is a sum of 2 squares if and only if p mod 4 != 3 (so 3 is not a sum of 2 squares, 5 is (2^2 + 1^2), 7 isn't, 11 isn't, 13 is (3^2 + 2^2), etc.